This Team Used Apache Cassandra… You Won’t Believe What Happened Next

You know that old saying, “If it seems too good to be true, it probably is?” We technologists should probably apply that saying to database vendor claims pretty regularly.
In the summer of 2014, the Parse.ly team finally kicked the tires on Apache Cassandra. I say “finally”, because after years of using other distributed database technologies on our real-time analytics problems, I was tired of hearing from technologists — even ones on my own team — saying that our problem domain was “so obviously a fit for Cassandra”, that I figured we should at least entertain the notion.
After all, Cassandra is a highly-available, linearly-scalable data store. It is supposedly battle-tested at Facebook, Apple, and Netflix scale. It is supposedly the key to Netflix’s horizontal and elastic scalability in the AWS cloud. It is supposedly built to let your ops staff sleep easily at night, handling relentless write volumes of hundreds of thousands per second with ease and grace. It supposedly has an unassailable reliability model that lets you pull the plug on nodes without intervention, thanks to cluster auto-healing. And here’s the kicker — it’s supposedly optimized for Parse.ly’s data set: analytics data, and especially for time series data.

That’s a lot of “supposedly’s!”
What we learned over the course of the next 6 months really, really surprised us. I think it’ll surprise you, too. We learned that Cassandra, though a very cool technology, is not a panacea for real-time analytics or time series problems. We also learned that the technology is loaded with traps that require deep knowledge of Cassandra internals to work around.
We also find the technology to very much violate the “principle of least surprise” — indeed, almost every Cassandra feature has some surprising behavior.
The rest of this article explores these surprises through the use of fun “Internet news style headlines” followed by a short explanation of the problem. We hope it helps other teams use Cassandra with more confidence and fewer battle scars.
Here’s a preview of the headlines:
- INDUSTRY SHOCKER: CQL is not SQL
- We Didn’t Use COMPACT STORAGE… You Won’t Believe What Happened Next
- REVEALED: \x01 Separators Are Not The Ugly Hack They Appear To Be
- Evil Cassandra Counters: They Still Hate Us! (Even in 2.1.x)
- Check Your Row Size: Too Wide, Too Narrow, or Just Right?
- “The Dress” Breaks the Internet — and, Our Database
- For Future Travelers: Here By Dragons!
- Postscript: Living with Cassandra
INDUSTRY SHOCKER: CQL is not SQL
Our team had studied Cassandra before the project had introduced CQL, the “Cassandra Query Language”, and the 2.x line of Cassandra releases. You would be wise to study Cassandra’s history before diving into CQL, because CQL has nothing to do with SQL, and any relationship will only lead you to surprises.
You see, in Cassandra 1.x, the data model is centered around what Cassandra calls “column families”. A column family contains rows, which are identified by a row key. The row key is what you need to fetch the data from the row. The row can then have one or more columns, each of which has a name, value, and timestamp. (A value is also called a “cell”). Cassandra’s data model flexibility comes from the following facts:
- column names are defined per-row
- rows can be “wide” — that is, have hundreds, thousands, or even millions of columns
- columns can be sorted, and ranges of ordered columns can be selected efficiently using “slices”
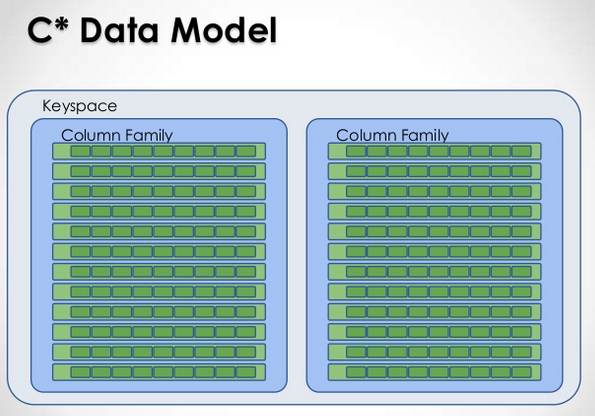
Cassandra’s data partitioning scheme comes from ensuring sharding and replication occurs on a row key basis. That is, ranges of row keys will establish cluster “shards”, and rows will be automatically replicated among cluster nodes.
Notice that I haven’t mentioned CQL yet. That’s because, CQL tries to hide every detail I described above from you, even though this knowledge is critical to running a Cassandra cluster. In CQL and Cassandra 2.x, column families are renamed to “tables”. Row keys become “primary keys” on those tables. A syntax that looks like a restricted subset of SQL (SELECT, INSERT, CREATE TABLE) offers a facade on these Cassandra facilities, but with none of the underlying SQL machinations.
The fact that rows can be wide or narrow falls out of how you design your CQL schema and how you use the resultant “tables” (that is, column families). We will discuss wide vs skinny rows later, so I’ll get there.
Here’s the core warning: CQL is SQL in the same way JavaScript is Java. (That is, it’s not.)
JavaScript was designed to look somewhat “Java-like”, because Java was trendy and well-understood by technologists when JavaScript was designed. But JavaScript is not Java. In fact, JavaScript, in all respects other than a superficial set of syntax similarities, couldn’t be more different than Java if it tried.
CQL was designed to look somewhat “SQL-like”, because SQL is trendy and well-understood by technologists today. But the relationship with SQL is the same: in all respects other than the superficial, it is a completely different beast.
I hope this warning helps. It will definitely help you interpret the following statement that is in Apache Cassandra’s Github README: “The Cassandra Query Language (CQL) is a close relative of SQL.” This is a false statement. You should ignore it. It’s more like a distant cousin — who later finds out she was actually adopted by her parents.
The way I read this line in the README is that the developers are excited, because CQL does actually make Cassandra easier to use. It does something important for the community: it unifies the client libraries around a single way of interacting with the database, like SQL did for many SQL databases. This is A Good Thing, but it doesn’t mean that CQL is anything like SQL.
There’s more to learn, so let’s keep going.
We Didn’t Use COMPACT STORAGE… You Won’t Believe What Happened Next
OK, so I cheated and re-used the headline format of this blog post itself, but I couldn’t resist. It just fit so well.
What’s COMPACT STORAGE, you ask?
Well, along with Cassandra 2.0 and CQL, the Cassandra project introduced some more capabilities that are built directly into CQL’s schema modeling capabilities. It tried to codify patterns from the community, specifically, ways of storing maps, lists, and sets of data inside a Cassandra row.
A Cassandra row is already sort of like an ordered map, where each column is a key in the map; so, storing maps/lists/sets in a Cassandra row is like storing maps/lists/sets inside an ordered map. This is an admirable goal, since it does provide some data modeling flexibility. Cassandra calls these CQL Collections, and, like sirens singing beautiful hymns off a sun-kissed shoreline, they seem very attractive.
CQL Collections required some enforced structure onto the rows that are stored in column families. This structure allows a mixture of map fields, list fields, and set fields to exist within a single logical table (remember: table = column family). Under the hood, Cassandra only knows about keys, column names, and values. So, this structure is built up by smartly inserting “marker columns” and embedding concatenated key names into column names appropriately. Imagine if in Python, rather than storing a dict in a dict, you needed to store the sub-dict keys inside the parent dict’s keys.
[code lang=text]
# “embedding” of unstructured data
points = {
“point1”: {“x”: 12, “y”: 10},
“point2”: {“x”: 8: “y”: 3},
# … and so on …
}
# vs “encoding” of unstructured data
points = {
“point1::”: “dict”
“point1::x”: 12,
“point1::y”: 10,
“point2::”: “dict”
“point2::x”: 8,
“point2::y”: 3,
# … and so on …
}
[/code]
CQL Collections don’t really “embed” structure into cells, so much as they “encode” structure into columns. The cost of all of this structure: data storage on disk.
To be fair, Cassandra operates with the assumption that “disk is cheap”, but in a simple example we had at Parse.ly where we attempted to use a CQL Map to store analytics data, we saw 30X data size overhead vs using a simpler storage format and Cassandra’s old storage format, now called COMPACT STORAGE. Ah, that’s where the name comes from: COMPACT, as in small, lightweight. Put another way, Cassandra and CQL’s new default storage format is NOT COMPACT, that is, large and heavyweight.

Now, the whole reason we were adopting Cassandra in the first place is because we have huge datasets. Terabytes upon terabytes of raw analytics and event data. Suffering a 30X data overhead for storage (and that’s even after compression) is not a trivial matter. We were actually hoping that Cassandra could store things more compactly than our raw data, but this wasn’t happening, due to the overhead of CQL Collections and the CQL 3.0 row format.
So, we did what any team that enjoys practicality over purity would do. We scrapped our hopes of using the “new shiny” and stuck with the appropriately-named COMPACT STORAGE. Though the Cassandra documentation is full of warnings about how COMPACT STORAGE is only for backwards-compatibility with CQL 2.0 and that this restricts your use of the more advanced features, what we found is that the cost of those features simply did not make sense at large data scale.
This team didn’t use COMPACT STORAGE, and the result was they got storage that wasn’t compact!
REVEALED: \x01 Separators Are Not The Ugly Hack They Appear To Be
Speaking of compact vs non-compact storage types, if we aren’t able to use Cassandra CQL 3.0 and CQL Maps to store unstructured data in Cassandra, how do we pull it off?
We decided to pick an extremely simple separated-value storage format for every analytics event, each of which goes into a column that is named with that analytics event identifier and timestamp. We lovingly labeled this scheme “xsv”, because the separator we chose to use is the Unicode escape character, \x01.
So, for example, in storing a visit to a specific URL from Twitter, we might store values like this:
[code lang=text]
name=d, ts=2015-02-01T08:00:01.123Z::
http://site.com/url1x01http://t.co/1234
name=d, ts=2015-02-01T08:00:05.832Z::
http://site.com/url2x01http://t.co/1235
[/code]
The way to read the xsv values is to imagine them being unpacked by Python that looks like this:
[code lang=python]
>>> url, urlref = xsv_parse(line)
>>> url
“http://site.com/url1”
>>> urlref
“http://t.co/1234”
[/code]
In other words, the keys for these separated values are not stored in Cassandra itself; instead, they are stored in our serialization/deserialization code.
This seems like a terribly ugly hack, but it’s actually really not.
The \x01 value shows up in a different color in Cassandra’s CQL shell, cqlsh. It is easy to split and serialize. It doesn’t require quoting of values, like traditional CSV would (because, every byte counts!). Of course, you need to worry about \x01’s showing up in your raw data, but you can escape these, and they are quite rare.
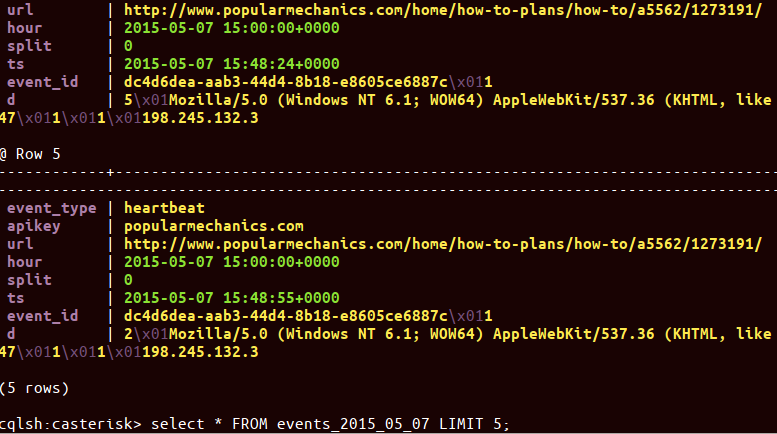
The downside is that the schema stored in each row is not “self-describing”, as it might be with CQL Maps. But, the storage savings are so tremendous that we can live with that. And, since we use a consistent order, we can “grow” our schema over time by simply appending new values on the right side of the serialization form.
Here’s the other amazing thing. The client performance of these xsv values is much, much better than the CQL Collections equivalent, and even better than a schema we tried where we actually modeled every field directly in the CQL schema. Why? Because the client would spend most of its time decoding the “structure” of the row, rather than decoding the actual values, in both of those cases.
I know what you’re thinking — why not use something like Avro or Protocol Buffers? We considered this, but felt that this would make Cassandra’s data storage a bit too inscrutable. You wouldn’t be able to meaningfully use the CQL shell — thus eliminating one of the main benefits of CQL. We were willing to throw out CQL 3.0 and CQL Collections, but not the entire idea of having a usable CQL shell!
We also did some calculations and found that xsv performed similarly for our data set, anyway — since most of our values are strings, the binary serialization approach doesn’t actually help much.
So, to store large gobs of unstructured data in Cassandra, we recommend COMPACT STORAGE with serialized values in an “xsv” format. They are more storage-efficient and more CPU- and I/O-efficient. Go figure! It smokes all the “official” ways of modeling unstructured data in Cassandra.
That means our team’s advice is to ignore all the advice against using COMPACT STORAGE in the docs, and ignore all the fancy new CQL 3 stuff. Pretty weird — but, unlike the marketed features, this scheme actually works!
Evil Cassandra Counters: They Still Hate Us! (Even in 2.1.x)
Oh, my. I was dreading this section. I got burned badly by Cassandra Counters.
I shudder even now to think about the six-or-so weeks of development time I lost trying to make Counters work for our use case.
If you watch a lot of Cassandra presentations online, you’ll hear different things about Counters from different people. Cassandra old-timers will say things like, “Counters are evil”, “Counters are a hack”, “Counters barely work”, “Counters are dangerous, “Never, ever use Counters…” — you get the idea.
When I’m in a good mood, I sometimes ask questions about Counters in the Cassandra IRC channel, and if I’m lucky, long-time developers don’t laugh me out of the room. Sometimes, they just call me a “brave soul”.
In Cassandra 2.x, things are more hopeful. Counters received several sprints of development and the feature was starting to be better understood. First, a bunch of fixes in 2.0.x that made Counters more reliable. Then, a whole new Counters implementation in 2.1.x that improved their performance, especially under contention.
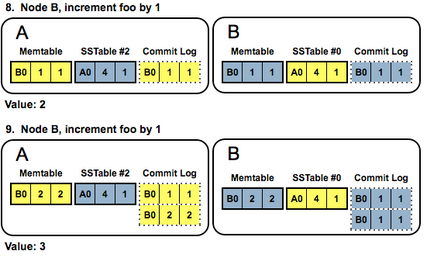
The reason Counters are so controversial and weird in the Cassandra community is because they seem to be at odds with Cassandra’s philosophy. Cassandra is meant to be a data store built on principles of immutability and idempotence. Incrementing a counter is a non-idempotent operation that seems to require an inherently mutable data store (like Redis or MongoDB).
Cassandra works around this by implementing Counter increments as “read-then-write” operation, similar to another Cassandra trap feature, Light-Weight Transactions (LWT). The implementation is clever and it works, but it does not have the same performance as plain Cassandra row/column INSERT’s, for which it is optimized.
Now, even if you can live with Cassandra’s different performance characteristics for Counters, you’ll discover other oddities. For example, column families that use counters have to live on their own, because the underlying storage is different. Counters can’t really be deleted — unless the delete is “definitive”, and even, then, there seem to be weird cluster bugs that surface with counter deletes. Related to counters not being deletable, you also learn that Cassandra’s time-to-live (TTL) features for data expiration simply do not work on Counters.
Finally, you’ll find that by opting into Counters, you threw out the baby with the bathwater — yes, you got a convenient durable data structure for storing counts, but you lost all the benefits of having an idempotent data store. This matters in analytics use cases, although we didn’t realize quite how much it mattered until we were well into it.
All of this is to say: Cassandra Counters — it’s a trap! Run!
Even in 2.1.x, when many of Cassandra Counters problems were fixed, we still find it’s a trap. Since we didn’t need Counters, we also decided to roll back to the “more stable” Cassandra line, 2.0.x. It still supports CQL, but has been in production longer, and is maintained as a parallel stable branch to 2.1.x.
Check Your Row Size: Too Wide, Too Narrow, or Just Right?
Remember when I mentioned how in Cassandra’s underlying data model, the row key determines how the system distributes your data?
It turns out, the most important data model challenge for Cassandra users is controlling your row size. In the same way a fashion magazine ebbs and flows on what the right waist size is for men and women, Cassandra ebbs and flows on the question of what the right row size is.
The short answer, that will be frustrating, is that you want your rows to be neither too wide, nor too narrow — but, just right. This is frustrating because you have no rules of thumb to go by. Cassandra theoretically supports rows with 2 billion columns, and is quite proud of this fact. But, you ask anyone in the community, and they will tell you — storing 2 billion columns in one row is a very, very bad idea. So, how many is right? 10,000? 100,000? A million? A hundred million?
We demanded answers, but we couldn’t get consistent ones. For our own data set, we settled on roughly 100,000 — and we also suggested that our average row should have many fewer columns than that — typically a few thousand. For our data set, this seems to strike the right balance between read performance and compaction/memory pressure on the cluster.
But, determining the right row size for your data will be an iterative process, and will require testing. So, think hard about it during schema design and during your integration tests. In our case, we decided to partition data by event type and on every tracked URL. We further partitioned the data by hour, so that the data for a single URL on a single day was stored in 24 row keys. This seemed to work well for 99.99% of our rows, until something awful happened.
“The Dress” Breaks the Internet — and, Our Database
The silly Internet meme about “The Dress” went around many of our customer sites, who are large news and information publishers. The result was that many customer URLs were receiving upwards of 40 million unique visitors per hour to a single URL. This meant that our partitioning scheme for Cassandra would get a “very wide row” — nowhere near 2 billion columns, to be sure, but definitely in the tens and hundreds of millions.
This put compaction pressure on our cluster and also led to some write contention.
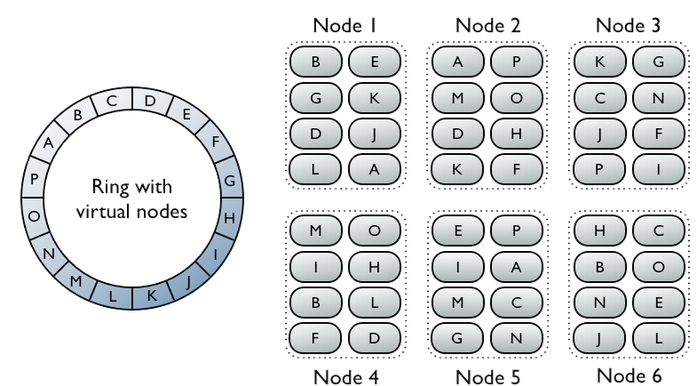
Unfortunately, we couldn’t come up with a more natural partitioning scheme that would handle this rare case, so, instead, we had to introduce a “synthetic partition key”. That is, we have another system that tracks very hot URLs in a lightweight way, and when they reach a certain threshold, we systematically “partition the partitions” using a split factor.
So, 40 million events might now be spread among 400 row keys, ensuring that each only holds 100,000 columns of data, keeping our row size “just right”.
This introduced operational complexity, but was necessary to make Cassandra work for our use case.
For Future Travelers: Here Be Dragons!
A well-seasoned technologist friend of mine was not at all surprised when I walked him through some of these issues we had with Cassandra. He said, “You honestly expected that adopting a data store at your scale would not require you to learn all of its internals?” He has a point. After all, we didn’t adopt Elasticsearch until we really grokked Lucene.
But what about time series and analytics data? The funny thing about Parse.ly’s use of Cassandra is that our original adoption of it was driven by the desire to utilize its “time series analytics” capabilities. But it turns out, without any capability to group, filter, or aggregate (the core functions of any OLAP system), Cassandra simply could not play that role. We had hoped that Counters would give us “basic aggregation” (by holding cumulative sums), but, no dice!
Instead, we ended up using it as a data staging area, where data sits before we index in our Lucene-based time series system. We discussed this a little bit over at the Elastic blog, in the article, “Pythonic Analytics with Elasticsearch”.
Now that we’ve come to understand its strengths and limitations, it works well in that role — because providing a time-ordered, durable, idempotent, distributed data store is something that Cassandra can handle.
If you adopt Cassandra for a large data use case, I recommend you heed the above advice:
- learn what CQL actually is;
- avoid CQL Collections;
- use COMPACT STORAGE;
- adopt custom serialization formats;
- don’t use counters;
- stay on 2.0.x “most-stable”;
- manage row size carefully;
- and, watch out for partitioning hotspots
With these guidelines in mind, you will likely end up with a better experience.
“If it’s too good to be true, it probably is.” Indeed.
But, overall, Cassandra is a powerful tool. It’s one of the few truly “AP” (Highly Available and Partition-Tolerant) data stores with a very powerful data distribution and cluster scale-out model. Its main fault is over-marketing its bugs as features, and trying too hard to make its quirky features appealing to the mass market, by dumbing them down.
For experienced distributed systems practitioners, adopt Cassandra with the comfort of knowing the scale of its existing deployments, but with the caution that comes from knowing that in large-scale data management, there is no silver bullet.
Postscript: Living with Cassandra
I asked Didier Deshommes, a long-time Parse.ly backend engineer, if he had any tips for newcomers. His tips are included here as the postscript to this article.
Though this article discussed many of the traps we hit with Cassandra, there are many resources online for how to model data “the Cassandra way”. These can serve as some positive instruction.
I find that modeling data in Cassandra involves essentially one trick with several variations (wide rows).
Although there are several Cassandra how-to and data modeling tutorials, I usually keep going back to only a handful of links when I want to refresh my memory on them. The funny thing about these links is that many of them come from around the time CQL was introduced, or even before.
The WHERE Clause
Writing data is so easy in Cassandra that you often forget how to read it efficiently. The best guide I know for knowing what you can get away with is Breaking Down the CQL Where Clause.
As a nice side effect, this will also inform how to structure your writes so that you can take advantage of some of these rules.
Time Series Models
Cassandra is a one-trick pony, so sometimes you need a little creativity for fitting it to your problem. When I’m feeling stuck and worried I might run out of wide row tricks, I go back to Advanced Time Series with Cassandra to give me ideas.
This builds on Cassandra modeling techniques developed in 2011, in Basic Time Series with Cassandra. I don’t go back to this older article as often, but it does introduce the well-worn idea of time-based rollups.
Tyler Hobbes
Tyler Hobbes, the author of the advanced time series post, also recently put out Basic Rules of Cassandra Data Modeling, which is a great place to get started. It’s the article I point newer Cassandra users to right away.
Tyler is the primary author of Cassandra’s CQL Python driver, so there is also much to learn from him via his public slides, such as:
- Intro to Cassandra — focuses on the “what makes Cassandra special” parts without marketing hype
- Cassandra for Python developers — these slides are interesting because they predate CQL
- Principles of Cassandra data modeling — visual aid for the above “rules of data modeling” blog post
Avoid the traps, embrace the tricks. Good luck!
Interested in Python, DevOps, and/or distributed systems? Want to work at a company dealing petabyte-scale data, real-time analytics, and cloud scaling challenges? Parse.ly is always looking for great talent for its small but nimble Python backend engineering and DevOps teams. Write an email to work@parsely.com with “Re: Cassandra” in the subject line.